वेब स्क्रैपिंग क्या है? वेबसाइट से डाटा कैसे कलेक्ट करें
विज्ञापन
वेब स्क्रेपर्स स्वचालित रूप से जानकारी और डेटा एकत्र करते हैं जो आमतौर पर केवल ब्राउज़र में एक वेबसाइट पर जाकर सुलभ होता है। स्वायत्त रूप से ऐसा करने से, वेब स्क्रैपिंग स्क्रिप्ट डेटा माइनिंग, डेटा विश्लेषण, सांख्यिकीय विश्लेषण और बहुत कुछ में संभावनाओं की दुनिया खोलती है।
क्यों वेब स्क्रैपिंग उपयोगी है
हम एक ऐसे दिन और उम्र में रहते हैं जहाँ जानकारी किसी भी अन्य समय की तुलना में अधिक आसानी से उपलब्ध है। आपके द्वारा पढ़े जा रहे इन बहुत से शब्दों को वितरित करने के लिए उपयोग किया जाने वाला बुनियादी ढांचा लोगों के इतिहास में लोगों के लिए पहले से कहीं अधिक ज्ञान, राय और समाचारों के लिए एक नाली है।
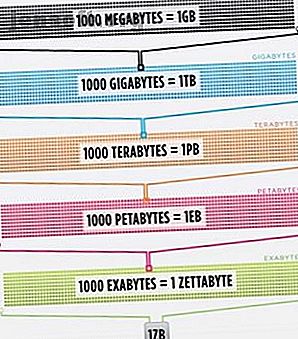
इतना कुछ, वास्तव में, सबसे चतुर व्यक्ति का मस्तिष्क, 100% दक्षता तक बढ़ गया (किसी को उसके बारे में एक फिल्म बनानी चाहिए), अभी भी अकेले संयुक्त राज्य अमेरिका में इंटरनेट पर संग्रहीत डेटा का 1/1000 वाँ हिस्सा नहीं ले पाएगा। ।
सिस्को ने 2016 में अनुमान लगाया था कि इंटरनेट पर ट्रैफ़िक एक zettabyte से अधिक है, जो 1, 000, 000, 000, 000, 000, 000, 000 बाइट्स या एक sextillion बाइट्स (आगे बढ़ो, sextillion पर खीसें) है। एक zettabyte Netflix स्ट्रीमिंग के बारे में चार हजार साल है। यदि आप निडर पाठक के बराबर होंगे, तो 500, 000 बार बिना रुके ऑफिस को शुरू से अंत तक स्ट्रीम करना था।

यह सब डेटा और जानकारी बहुत डराने वाली है। यह सब सही नहीं है। इसका अधिकांश हिस्सा रोजमर्रा की जिंदगी के लिए प्रासंगिक नहीं है, लेकिन अधिक से अधिक डिवाइस इस जानकारी को दुनिया भर के सर्वरों से लेकर हमारी आंखों तक और उसके दिमाग में पहुंचा रहे हैं।
जैसा कि हमारी आंखें और दिमाग वास्तव में इस जानकारी को संभाल नहीं सकते हैं, वेब स्क्रैपिंग इंटरनेट से प्रोग्राम डेटा एकत्र करने के लिए एक उपयोगी विधि के रूप में उभरा है। वेब स्क्रैपिंग स्थानीय स्तर पर डेटा को बचाने के लिए वेबसाइटों से डेटा निकालने के कार्य को परिभाषित करने के लिए सार शब्द है।
एक प्रकार के डेटा के बारे में सोचें और आप शायद इसे वेब को स्क्रैप करके एकत्र कर सकते हैं। रियल एस्टेट लिस्टिंग, स्पोर्ट्स डेटा, आपके क्षेत्र में व्यवसायों के ईमेल पते और यहां तक कि आपके पसंदीदा कलाकार के गीत भी सभी को एक छोटी स्क्रिप्ट लिखकर सहेजे जा सकते हैं।
ब्राउज़र वेब डेटा कैसे प्राप्त करता है?
वेब स्क्रैपर्स को समझने के लिए, हमें यह समझने की आवश्यकता होगी कि वेब पहले कैसे काम करता है। इस वेबसाइट पर जाने के लिए, आपने या तो "makeuseof.com" को अपने वेब ब्राउज़र में टाइप किया है या आपने दूसरे वेब पेज से लिंक पर क्लिक किया है (हमें बताएं कि गंभीरता से हम कहां जानना चाहते हैं)। किसी भी तरह से, अगले कुछ चरण समान हैं।
सबसे पहले, आपका ब्राउज़र आपके द्वारा दर्ज किए गए URL को ले जाएगा या उस पर क्लिक कर देगा (प्रो-टिप: अपने ब्राउज़र के निचले भाग में URL देखने के लिए लिंक पर होवर करें, क्लिक करने से पहले उसे पंक करने से बचें) और भेजने के लिए "अनुरोध" बनाएँ एक सर्वर के लिए। सर्वर फिर अनुरोध को संसाधित करेगा और एक प्रतिक्रिया वापस भेजेगा।
सर्वर की प्रतिक्रिया में HTML, जावास्क्रिप्ट, सीएसएस, JSON, और आपके वेब ब्राउज़र को देखने के आनंद के लिए एक वेब पेज बनाने की अनुमति देने के लिए आवश्यक अन्य डेटा शामिल हैं।
वेब तत्वों का निरीक्षण
आधुनिक ब्राउज़र हमें इस प्रक्रिया के बारे में कुछ विवरण देते हैं। विंडोज पर Google क्रोम में आप Ctrl + Shift + I या राइट क्लिक करके इंस्पेक्ट का चयन कर सकते हैं। विंडो फिर एक स्क्रीन पेश करेगी जो निम्न की तरह दिखती है।

विकल्पों की टैब्ड सूची विंडो के शीर्ष को दर्शाती है। ब्याज की अभी नेटवर्क टैब है। यह नीचे दिखाए गए अनुसार HTTP ट्रैफ़िक के बारे में विवरण देगा।

निचले दाएं कोने में हम HTTP अनुरोध के बारे में जानकारी देखते हैं। URL वह है जिसकी हम अपेक्षा करते हैं, और "विधि" एक HTTP "GET" अनुरोध है। प्रतिक्रिया से स्थिति कोड 200 के रूप में सूचीबद्ध है, जिसका अर्थ है कि सर्वर ने अनुरोध को वैध के रूप में देखा था।
स्थिति कोड के नीचे रिमोट एड्रेस होता है, जो सार्वजनिक होता है makeuseof.com सर्वर का आईपी एड्रेस। क्लाइंट को यह पता DNS प्रोटोकॉल के माध्यम से मिलता है कि क्यों DNS सेटिंग्स बदलना आपके इंटरनेट की गति को बढ़ाता है क्यों DNS सेटिंग्स को बदलना आपकी इंटरनेट की गति को बढ़ाता है आपकी DNS सेटिंग्स उन मामूली जुड़वाओं में से एक है जो दिन-प्रतिदिन की इंटरनेट स्पीड पर बड़े रिटर्न दे सकते हैं। अधिक पढ़ें ।
अगले अनुभाग में प्रतिक्रिया के बारे में विवरण सूचीबद्ध है। प्रतिक्रिया हेडर में न केवल स्थिति कोड होता है, बल्कि उस डेटा या सामग्री का प्रकार भी होता है जिसमें प्रतिक्रिया होती है। इस मामले में, हम एक मानक एन्कोडिंग के साथ "टेक्स्ट / html" देख रहे हैं। यह हमें बताता है कि प्रतिक्रिया सचमुच वेबसाइट को रेंडर करने के लिए HTML कोड है।

अन्य प्रकार की प्रतिक्रियाएँ
इसके अतिरिक्त, सर्वर डेटा वस्तुओं को GET अनुरोध की प्रतिक्रिया के रूप में, वेब पेज को रेंडर करने के लिए केवल HTML के बजाय वापस कर सकते हैं। एक वेबसाइट के एप्लिकेशन प्रोग्रामिंग इंटरफ़ेस (या एपीआई) एपीआई क्या हैं, और कैसे खुले एपीआई इंटरनेट बदल रहे हैं, एपीआई क्या हैं, और खुले एपीआई कैसे बदलते हैं इंटरनेट क्या आपने कभी सोचा है कि आपके कंप्यूटर और आपके द्वारा देखी जाने वाली वेबसाइटों पर कैसे कार्यक्रम "बात करते हैं" एक दूसरे को? अधिक पढ़ें आमतौर पर इस प्रकार के विनिमय का उपयोग करता है।
नेटवर्क टैब को ऊपर दिखाए अनुसार, आप देख सकते हैं कि क्या इस प्रकार का विनिमय है। क्रॉसफ़िट ओपन लीडरबोर्ड की जांच करते समय तालिका को डेटा से भरने का अनुरोध दिखाया गया है।

प्रतिक्रिया पर क्लिक करके, वेबसाइट को रेंडर करने के लिए HTML कोड के बजाय JSON डेटा दिखाया जाता है। JSON में डेटा एक स्तरित, उल्लिखित सूची में लेबल और मूल्यों की एक श्रृंखला है।

HTML कोड को मैन्युअल रूप से पार्स करना या JSON की हज़ारों की / वैल्यू जोड़ी के माध्यम से जाना मैट्रिक्स को पढ़ने जैसा है। पहली नज़र में, यह जिबरिश जैसा दिखता है। मैन्युअल रूप से इसे डीकोड करने के लिए बहुत अधिक जानकारी हो सकती है।
बचाव के लिए वेब स्क्रैपर्स!
अब इससे पहले कि आप यहां से बाहर निकलने के लिए नीली गोली के लिए पूछें, आपको पता होना चाहिए कि हमें HTML कोड को मैन्युअल रूप से डिकोड नहीं करना है! अज्ञानता आनंद नहीं है, और यह स्टेक स्वादिष्ट है।
एक वेब खुरचनी आपके लिए ये कठिन कार्य कर सकती है The Scrapestack API Makes It Easy to Scrape Websites for Data The Scrapestack API Makes It Easy to Scrape Websites for Data एक शक्तिशाली और सस्ती वेब स्क्रैपर की तलाश में है? स्क्रैपस्टैक एपीआई शुरू करने के लिए स्वतंत्र है और कई उपयोगी उपकरण प्रदान करता है। अधिक पढ़ें । स्क्रैपिंग फ्रेमवर्क पायथन, जावास्क्रिप्ट, नोड, और अन्य भाषाओं में उपलब्ध हैं। स्क्रैपिंग शुरू करने का सबसे आसान तरीका पायथन और सुंदर सूप का उपयोग करके है।
अजगर के साथ एक वेबसाइट स्क्रैपिंग
प्रारंभ करना केवल कुछ पंक्तियों की कोड लेता है, जब तक कि आपके पास पायथन और ब्यूटीफुल स्थापित है। एक वेबसाइट के स्रोत को प्राप्त करने के लिए यहां एक छोटी स्क्रिप्ट है और ब्यूटीफुल को इसका मूल्यांकन करने दें।
from bs4 import BeautifulSoup import requests url = "http://www.athleticvolume.com/programming/" content = requests.get(url) soup = BeautifulSoup(content.text) print(soup) बहुत सरलता से, हम किसी URL पर GET अनुरोध कर रहे हैं और फिर किसी ऑब्जेक्ट में प्रतिक्रिया डाल रहे हैं। ऑब्जेक्ट को प्रिंट करना URL के HTML स्रोत कोड को प्रदर्शित करता है। यह प्रक्रिया वैसी ही है जैसे हम मैन्युअल रूप से वेबसाइट पर जाते हैं और व्यू सोर्स पर क्लिक करते हैं।
विशेष रूप से, यह एक वेबसाइट है जो हर दिन क्रॉसफ़िट-स्टाइल वर्कआउट पोस्ट करती है, लेकिन प्रति दिन केवल एक। हम प्रत्येक दिन वर्कआउट प्राप्त करने के लिए अपने स्क्रैपर का निर्माण कर सकते हैं, और फिर इसे वर्कआउट की सूची में जोड़ सकते हैं। अनिवार्य रूप से, हम ऐसे वर्कआउट्स का टेक्स्ट-आधारित ऐतिहासिक डेटाबेस बना सकते हैं, जिन्हें हम आसानी से खोज सकते हैं।
ब्यूफिउलसूप का जादू अंतर्निहित एचटीएमएल () फ़ंक्शन का उपयोग करके सभी HTML कोड के माध्यम से खोज करने की क्षमता है। इस विशिष्ट मामले में, वेबसाइट कई "वर्ग-ब्लॉक-सामग्री" टैग का उपयोग करती है। इसलिए, स्क्रिप्ट को उन सभी टैग के माध्यम से लूप करने की आवश्यकता है और हमें एक दिलचस्प लगता है।
इसके अतिरिक्त, की एक संख्या हैं
अनुभाग में टैग। स्क्रिप्ट इनमें से प्रत्येक टैग से सभी पाठ को एक स्थानीय चर में जोड़ सकती है। ऐसा करने के लिए, स्क्रिप्ट में एक सरल लूप जोड़ें:
for div_class in soup.findAll('div', {'class': 'sqs-block-content'}): recordThis = False for p in div_class.findAll('p'): if 'PROGRAM' in p.text.upper(): recordThis = True if recordThis: program += p.text program += '\n' देखा! एक वेब खुरचनी पैदा होती है।
स्केलिंग अप स्क्रैपिंग
आगे बढ़ने के लिए दो रास्ते मौजूद हैं।
वेब स्क्रैपिंग का पता लगाने का एक तरीका पहले से निर्मित उपकरणों का उपयोग करना है। वेब स्क्रेपर (महान नाम!) के 200, 000 उपयोगकर्ता हैं और उपयोग करने के लिए सरल है। इसके अलावा, पार्स हब उपयोगकर्ताओं को एक्सेल और Google शीट में स्क्रैप किए गए डेटा को निर्यात करने की अनुमति देता है।
इसके अतिरिक्त, वेब स्क्रैपर एक क्रोम प्लग-इन प्रदान करता है जो यह कल्पना करने में मदद करता है कि एक वेबसाइट कैसे बनाई गई है। सबसे अच्छा, नाम से देखते हुए, ऑक्टोपैर्स है, जो एक सहज ज्ञान युक्त अंतरफलक के साथ एक शक्तिशाली खुरचनी है।
अंत में, अब जब आप वेब स्क्रैपिंग की पृष्ठभूमि जानते हैं, तो अपने छोटे वेब स्क्रैपर को क्रॉल करने और चलाने में सक्षम होने के लिए एक वेबसाइट से एक मूल वेब क्रॉलर का निर्माण कैसे करें वेबसाइट क्या आप कभी किसी वेबसाइट से जानकारी प्राप्त करना चाहते हैं? आप वेबसाइट पर नेविगेट करने के लिए एक क्रॉलर लिख सकते हैं और सिर्फ वही निकाल सकते हैं जो आपको चाहिए। अधिक पढ़ें अपने आप में एक मजेदार प्रयास है।
इसके बारे में अधिक जानें: पायथन, वेब स्क्रैपिंग।

